Precision and Recall
In a previous blog-post, we discussed the use of the so-called word-error-rate (WER) in evaluating the performance of automatic speech recognition (ASR) systems.
WER is a common measure for such evaluations and provides an adequate measure for applications such as sub-titling, where the correct transcription of every word is of importance. However, it falls short of capturing the essence of performance in other applications where the detection of key-terminology is of primary importance.
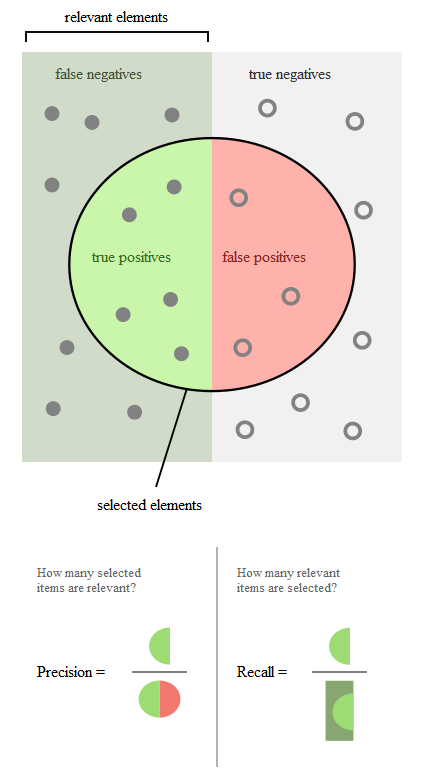
Diagram 1: Precision and recall, by Walber [1]
The application of ASR within the iTalk2Learn project concerns the latter type of applications – the detection of mathematical terminology as well as the detection of terminology leading to insights about the mental state of students. For these types of applications, evaluation measures from the area of information retrieval are more appropriate. Precision and recall as well as their harmonic mean, the f-measure, are typically used in this context.
For iTalk2Learn, precision corresponds to the fraction of correctly identified keywords over all identified keywords, whereas recall is the percentage of identified keywords over all keywords which should have been identified. Precision and recall can both be defined in terms of true and false positives and negatives, as depicted in the following diagram [1].
True Positives: keywords which occur in the audio and which are detected by the system.
False positives: keywords which are detected by the system but which aren’t actually uttered by the student.
False Negatives: keywords which are uttered by the student but not detected by the system.
True Negatives: everything else.
The resulting F-measure is then defined as the harmonic mean:
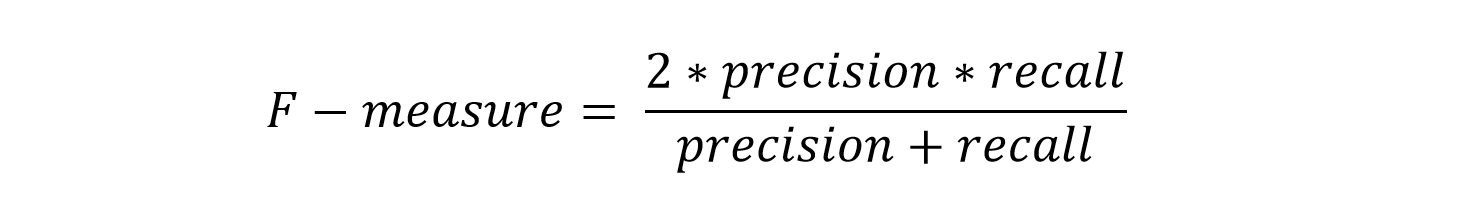
Precision and recall are usually related in an inverse manner: higher precision typically results in lower recall and vice-versa. The F-measure combines these two measures to arrive at a combined rate; often the point of equal-error-rate (EER) is cited in performance evaluations.
Different kinds of errors might be associated with different costs (not necessarily of a monetary nature). Certain kinds of applications may require a higher rate of precision, allowing for lower recall numbers. For instance, such a setup is required for applications where low false alarm rates are of importance. Other kinds of applications may favour higher recall, sacrificing precision (e.g. where all occurrences of certain kinds of data have to be detected by false-detections and are accepted up to a certain rate).
Within iTalk2Learn, the appearance or absence of certain kinds of terminology will be evaluated using precision and recall. Since processing for both, the detection of mathematical terminology as well as terminology leading to information about the student’s mental state are carried out not on single words or individual phrases, but rather on transcripts spanning a longer period of time. These longer segments will form the basis for all evaluations.
Furthermore, for some applications, the mere presence or absence of key-terminology (regardless of the multiplicity of item), might be sufficient, resulting in a binary evaluation of precision and recall.
Within iTalk2Learn, these measures will be evaluated on a test-set consisting of audio-files recorded in German and English. The test-set comprises phrases containing key terminology as well as phrases which do not contain any relevant wording in order to allow for assessment of precision and recall under realistic conditions.
References
[1] Walber (2014) Precisionrecall. Own work. Licensed under CC BY-SA 4.0 via Wikimedia Commons – http://commons.wikimedia.org/wiki/File:Precisionrecall.svg#/media/File:Precisionrecall.svg.



{kind=link}